ISI News
Move Over, Siri! USC Viterbi Researchers Develop Improv-based Chatbot

What would conversations with Alexa be like if she was a regular at The Second City?
Jonathan May, research lead at the USC Information Sciences Institute (ISI) and research assistant professor of computer science at USC’s Viterbi School of Engineering, is exploring this question with Justin Cho, an ISI programmer analyst and prospective USC Viterbi Ph.D. student, through their Selected Pairs Of Learnable ImprovisatioN (SPOLIN) project. Their research incorporates improv dialogues into chatbots to produce more engaging interactions.
The SPOLIN research collection is made up of over 68,000 English dialogue pairs, or conversational dialogues of a prompt and subsequent response. These pairs model yes-and dialogues, a foundational principle in improvisation that encourages more grounded and relatable conversations. After gathering the data, Cho and May built SpolinBot, an improv agent programmed with the first yes-and research collection large enough to train a chatbot.
The project research paper, “Grounding Conversations with Improvised Dialogues,” is being presented on July 6 at the Association of Computational Linguistics conference, held July 5-10.
Finding Common Ground
May was looking for new research ideas in his work. His love for language analysis had led him to work on Natural Language Processing (NLP) projects, and he began searching for more interesting forms of data he could work with.
“I’d done some improv in college and pined for those days,” he said. “Then a friend who was in my college improv troupe suggested that it would be handy to have a ‘yes-and’ bot to practice with, and that gave me the inspiration—it wouldn’t just be fun to make a bot that can improvise, it would be practical!”
The deeper May explored this idea, the more valid he found it to be. Yes-and is a pillar of improvisation that prompts a participant to accept the reality that another participant says (“yes”) and then build on that reality by providing additional information (“and”). This technique is key in establishing a common ground in interaction. As May put it, “Yes-and is the improv community’s way of saying ‘grounding.’”
Yes-ands are important because they help participants build a reality together. In movie scripts, for example, maybe 10-11% of the lines can be considered yes-ands, whereas in improv, at least 25% of the lines are yes-ands. This is because, unlike movies, which have settings and characters that are already established for audiences, improvisers act without scene, props, or any objective reality.
“Because improv scenes are built from almost no established reality, dialogue taking place in improv actively tries to reach mutual assumptions and understanding,” said Cho. “This makes dialogue in improv more interesting than most ordinary dialogue, which usually takes place with many assumptions already in place (from common sense, visual signals, etc.).”
But finding a source to extract improv dialogue from was a challenge. Initially, May and Cho examined typical dialogue sets such as movie scripts and subtitle collections, but those sources didn’t contain enough yes-ands to mine. Moreover, it can be difficult to find recorded, let alone transcribed, improv.

Example of “Yes, and” interaction (“Yes” in blue, “and” in orange)
The Friendly Neighborhood Improv Bot
Before visiting USC as an exchange student in Fall 2018, Cho reached out to May, inquiring about NLP research projects that he could participate in. Once Cho came to USC, he learned about the improv project that May had in mind.
“I was interested in how it touched on a niche that I wasn’t familiar with, and I was especially intrigued that there was little to no prior work in this area,” Cho said. “I was hooked when Jon said that our project will be answering a question that hasn’t even been asked yet: the question of how modeling grounding in improv through the yes-and act can contribute to improving dialogue systems.”
Cho investigated multiple approaches to gathering improv data. He knocked on doors of Hollywood improv clubs, but they didn’t respond to his requests. He tried recording live improv performances in USC undergraduate acting classes, but the recording quality was too low. After watching and listening to tons of TV shows and podcasts, he finally came across Spontaneanation, an improv podcast hosted by prolific actor and comedian Paul F. Tompkins that ran from 2015 to 2019.
With its open-topic episodes, about a good 30 minutes of continuous improvisation, high quality recordings, and substantial size, Spontaneanation was the perfect source to mine yes-ands from for the project. The duo fed their Spontaneanation data into a program, and SpolinBot was born.
“One of the cool parts of the project is that we figured out a way to just use improv,” May explained. “Spontaneanation was a great resource for us, but is fairly small as data sets go; we only got about 10,000 yes-ands from it. But we used those yes-ands to build a classifier (program) that can look at new lines of dialogue and determine whether they’re yes-ands.”
Working with improv dialogues first helped the researchers find yes-ands from other sources as well, as most of the SPOLIN data comes from movie scripts and subtitles. “Ultimately, the SPOLIN corpus contains more than five times as many yes-ands from non-improv sources than from improv, but we only were able to get those yes-ands by starting with improv,” May said.
SpolinBot has a few controls that can refine its responses, taking them from safe and boring to funny and wacky, and also generates five response options that users can choose from to continue the conversation.
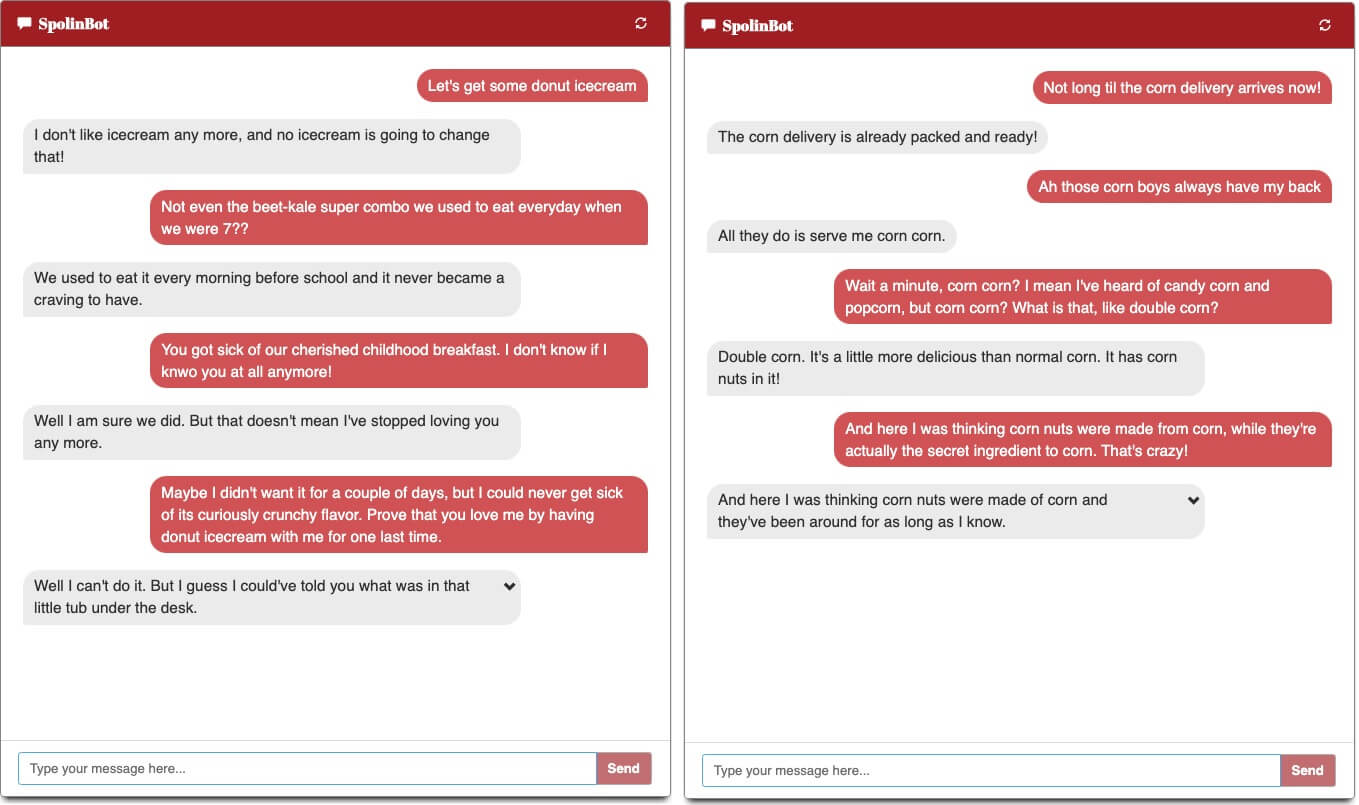
Examples of conversations with SpolinBot (bot responses in grey)
SpolinBot #Goals
The duo has a lot of plans for SpolinBot, along with extending its conversational abilities beyond yes-ands. “We want to explore other factors that make improv interesting, such as character-building, scene-building, ‘if this (usually an interesting anomaly) is true, what else is also true?,’ and call-backs (referring to objects/events mentioned in previous dialogue turns),” Cho said. “We have a long way to go, and that makes me more excited for what I can explore throughout my PhD and beyond.”
May echoed Cho’s sentiments. “Ultimately, we want to build a good conversational partner and a good creative partner,” he said, noting that even in improv, yes-ands only mark the beginning of a conversation. “Today’s bots, SpolinBot included, aren’t great at keeping the thread of the conversation going. There should be a sense that both participants aren’t just establishing a reality, but are also experiencing that reality together.”
That latter point is key, because, as May explained, a good partner should be an equal, not subservient in the way that Alexa and Siri are. “I’d like my partner to be making decisions and brainstorming along with me,” he said. “We should ultimately be able to reap the benefits of teamwork and cooperation that humans have long benefited from by working together. And the virtual partner has the added benefit of being much better and faster at math than me, and not actually needing to eat!”
Head over here to meet SpolinBot for yourself. If you’d like to contribute to the research project, be sure to submit your conversation when complete.
Published on
Last updated on